Building Stock Exchanges in the Cloud: part 1
Exploring how modern exchanges achieve low latency in the cloud, drawing insights from various exchanges design referrences
Introduction
Building a stock exchange is one of the most demanding distributed systems challenges in software engineering. Unlike traditional web applications where sub-second response times are acceptable, exchanges must process orders in microseconds, handle millions of messages per second, and maintain perfect fairness and reliability—all while operating during the designated market hours or 24/7.
This post explores the key principles, technologies, and architectural patterns that make modern cloud-based exchanges possible by collecting all referenes that Ive got to learn or experience.
Key characteristics
Latency
In financial markets, latency directly translates to money and risk for the trade. A millisecond advantage can mean the difference between executing a profitable trade and watching it slip away. The latency sensitivity spectrum is stark:
- Less latency sensitive: Reporting, risk calculations (time equivalent: light traveling from the sun)
- Ultra-low latency: High-frequency trading (time equivalent: light traveling ~150 miles)
Faireness
For exchanges, fairness is paramount. If one trader has a 1ms latency advantage over another, they gain an unfair advantage in market making and order execution. This creates a fundamental requirement: exchanges must maintain consistent, minimal latency for all participants while ensuring no single participant can gain an unfair advantage through connectivity differences.
Throughput and Scale
Exchanges must handle both steady-state and spiking workloads. Coinbase’s system is designed to handle 100k messages per second. However with the ability to spike during volatile market conditions or peak time there could be 500K to millons messages per second in the system.
Reliability
24/7 operation at p99 performance is non-negotiable. Any downtime or performance degradation can result in:
- Lost trading opportunities
- Market participant dissatisfaction
- Regulatory compliance issues
High level system design
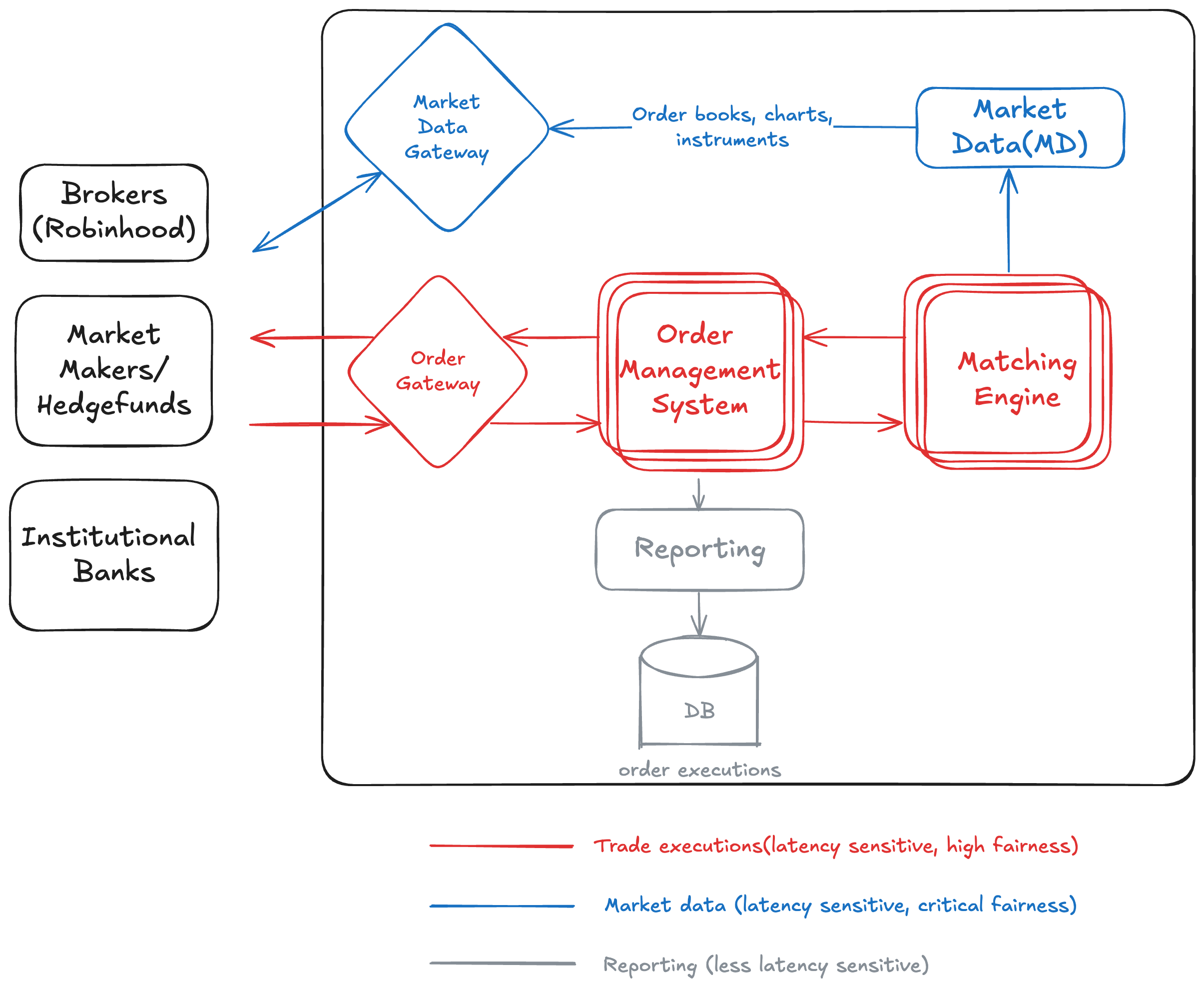
Market Participants
External clients interacting with the exchange:
- Brokers
- Market Makers / Hedge Funds
- Institutional Banks
Order Gateway
- Entry point for all incoming client orders.
- Performs validation, risk checks, and routing.
- Sends validated orders into the order management system.
- Handles highly latency-sensitive traffic.
Order Management System (OMS)
- Manages lifecycle of orders inside the exchange.
- Handles order creation, modification, cancellation, and state tracking.
- Connects client order flow to the matching engine.
Matching Engine
- Central component maintaining the limit order book.
- Matches buy and sell orders using price-time priority.
- Handles the most latency-critical processing in the exchange.
Market Data Gateway
- Receives market data updates from internal systems.
- Distributes order books, charts, and instrument data to external participants.
- Handles fairness-critical data dissemination for all consumers.
Market Data (MD) Publisher
- Produces real-time market data from the matching engine.
- Publishes depth, trades, and order book updates.
- Sends this data to the market data gateway.
Reporting Service
- Processes executed trades and order events.
- Generates reports for compliance, analytics, and post-trade functions.
- Writes data into a persistent database.
Database
- Stores order executions, trade history, and audit logs.
- Designed for durability and reliability rather than low latency.
Matching Engine and Order Management System Design
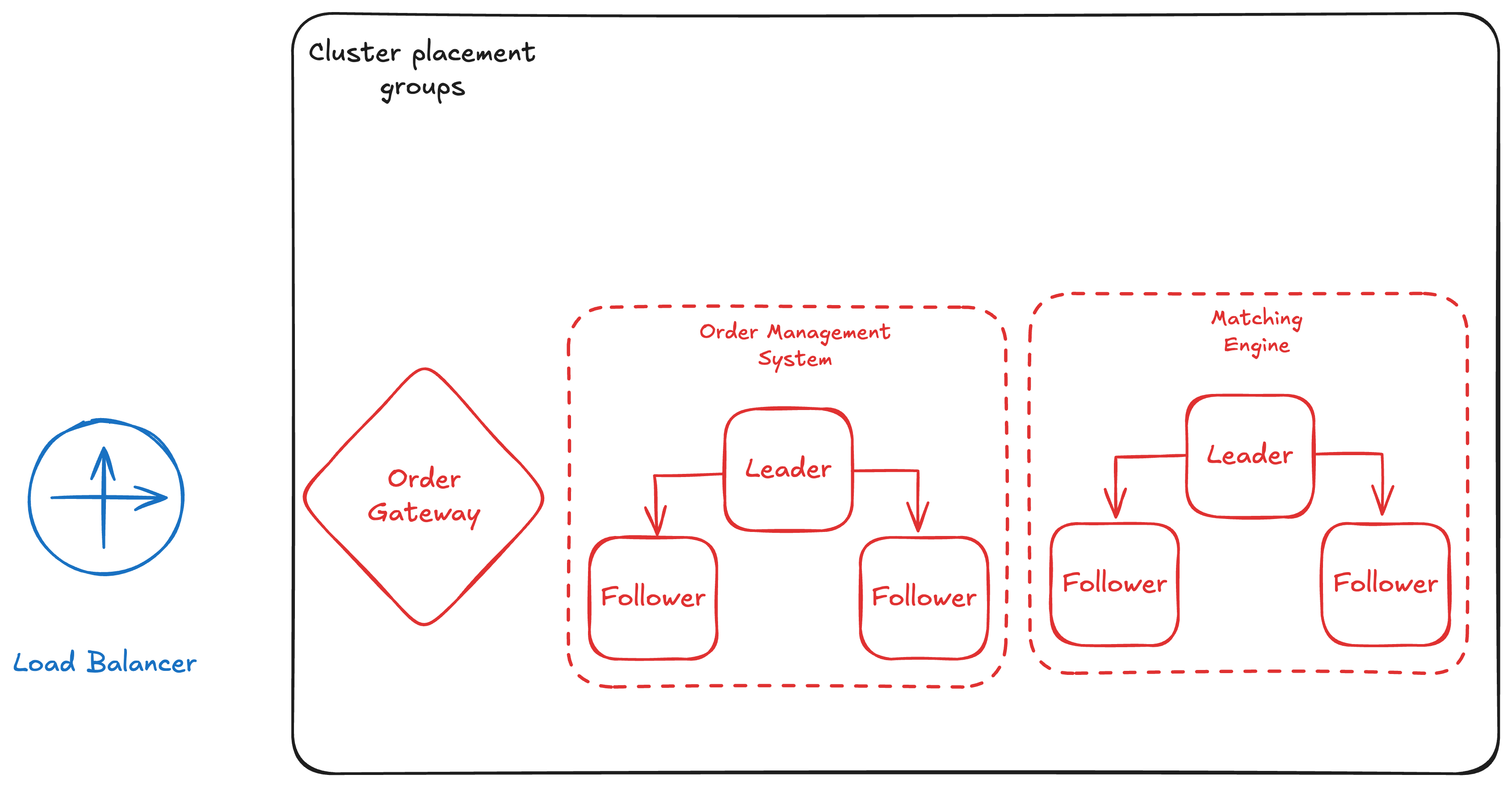
The matching engine and order management systems are implemented as distributed systems. They are stateful, replicating their data through logs, so the architecture must favor low network and disk I/O latency. We design these components around a single-threaded application loop to avoid locking contention; queuing enforces ordering for consistent, deterministic behavior.
AWS Services for Ultra-Low-Latency Trading
EC2 Instance options for High Performance
AWS offers several instance families optimized for single-threaded CPU performance, which is critical for deterministic, low-latency trading systems. Because Raft log replication demands fast, predictable disk I/O, favor instances with high-performance local NVMe storage.
Instance Family
- z1d instances: High-frequency Intel processors with sustained all-core turbo frequency [5]
- X2iezn instances: Intel Xeon processors optimized for memory-intensive workloads
- r7iz, c6in, m5zn instances: Balanced compute and memory options
The choice depends on your specific workload characteristics. CPU-bound matching engines benefit from the z1d family. z1d instances are VM instances that expose only a subset of physical CPU cores, all from a single NUMA node, resulting in reduced CPU cache penalties. Single-threaded systems using core pinning and C-State tuning achieve stable tail latencies. These instances offer a sustained all-core frequency of up to 4.0 GHz, providing consistently fast performance at the 99th percentile. NVMe’s instance store given better disk IO performance to sustain the RAFT cluster performance.
In contrast, order management systems may require the higher memory bandwidth provided by the X2iezn family.
Instance Tenancy and Provisioning
- Dedicated: Dedicated Instances are Amazon EC2 instances that run in a VPC on hardware that’s dedicated to a single customer. Your Dedicated instances are physically isolated at the host hardware level from instances that belong to other AWS accounts.
- Dedicated host: Dedicated Hosts to launch Amazon EC2 instances on physical servers that are dedicated for your use. Dedicated Hosts give you additional visibility and control over how instances are placed on a physical server, and you can reliably use the same physical server over time.
- On-demand: Standard virtual machines that share the underlying physical host with other tenants. You pay by the hour/second and capacity is allocated dynamically.
In AWS’s Dedicated tenancy model, virtualization overhead and cross-tenant interference are minimized, so low-latency system optimizations—such as tuning network stack, pinning processes/threads/interrupts to CPU cores, or using busy-spin threads—behave predictably with expected results, unlike in some other clouds. Dedicated VMs in this model behave much closer to bare-metal machines. This results in improved performance consistency (especially for tail latencies), even though the VM is still technically virtualized. However, the primary tradeoff is an added cost premium of about 10–15%. Additionally,
Cluster Placement Groups
Perhaps the most critical AWS feature for exchange architectures is EC2 Cluster Placement Groups. This ensures instances are placed in the same availability zone with the lowest possible network latency between them.
With EC2 networking is capped at 5Gbps, no matter how much total bandwidth the instance has. However, when your instances are in a cluster placement group, this per-flow limit increases to 10Gbps. With the parition plaement groups instances dont share the pack/host unit with instances in another partition for the resiliency purposes.
By using cluster placement groups, Coinbase was able to achieve amazing speed: their internal round-trip latency was under 1ms, and trading operations happened in single digit microseconds[1]. Similar way, testing with Aeron clusters on AWS also showed strong results—handling 100,000 messages per second with each message delivered in just 43 to 66 microseconds. Without cluster placement groups, your servers could be spread out, causing random slowdowns and making fast, fair trading impossible[2].
Network Architecture
For ultra-low latency, you need to minimize network hops:
- VPC Peering vs Transit Gateway: VPC peering provides lower latency (fewer hops) but less flexibility. For hot-path components, VPC peering is often preferred.
- AWS PrivateLink: Some of the benefits of private connectivity without having to cross connect directly in the datacenter or leave the traffic over the internet.
- Single Availability Zone: Keeping all hot-path components in a single AZ minimizes cross-AZ latency.
- Elastic Network Adapter (ENA) Express: Enhanced networking with lower latency and higher throughput. Amazon linux comes with the right ENA driver, however other distros need to make sure about ENA drivers are installed[3].
- Elastic Fabric Adapter(EFA): EFA could be used to reduce the latency by few more microseconds with the kernel bypass tequniques.
Note: Kernel bypass approaches such as DPDK introduce trade-offs—they make debugging network operations difficult because traditional tools or instrumentation/metrics won’t work in such setups.
Compute Cluster for Applications
- EC2 with an autoscaler: Offers the most performance-efficient option for latency-critical workloads.
- Containers (ECS/Kubernetes): Containers provide a ubiquitous packaging format, and tools like ECS or Kubernetes supply turnkey ecosystems to deploy, scale, and operate applications.
Given these trade-offs, running critical workloads such as the matching engine or order management system on EC2 remains the pragmatic choice. Could ECS or Kubernetes work? Possibly, but performance constraints make them a secondary option today. That said, the Kubernetes ecosystem continues to address low-latency challenges. For example, recent Cilium (Kubernetes networking) benchmarks with the Netkit data plane show latency approaching non-container level as running the application on the host, and in some cases outperforming traditional east-west networking flows(such as for the RAFT cluster use case)[10].
Service over the RAFT - Latency and Resiliency
This part of design dont highlight any important services from AWS, however some aspects this service is tested well the AWS envrionment and some statistics are available[6]
Lets understand the in the microdetails, how the Order Management System(OMS) and Matching Engine designed to not only achive the ultra-low latency but alos realibility with the auto failover in few microseconds wihtout any data loss.
Sysem design for the RAFT cluster
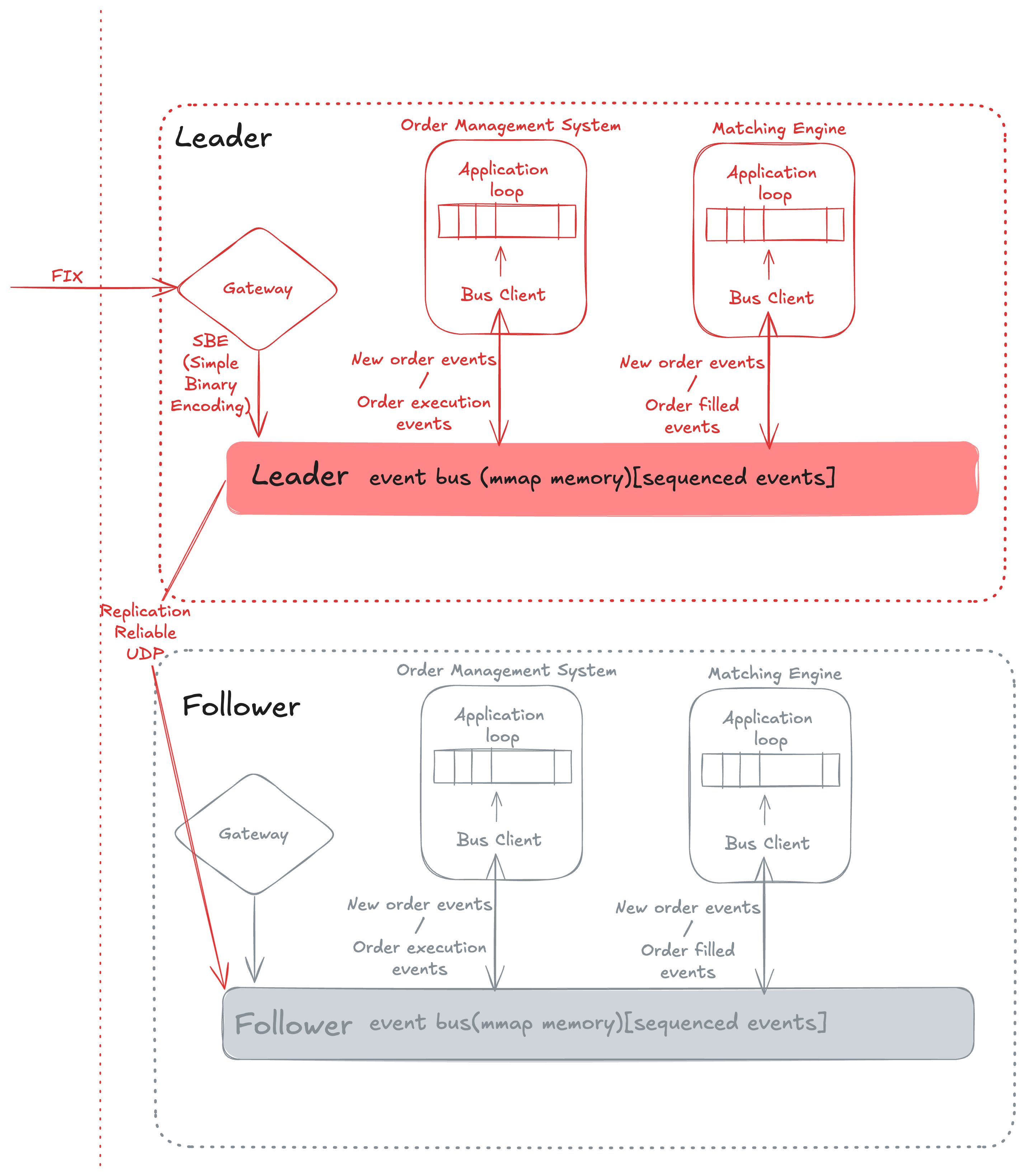
-
Built the hot path around a single-threaded, event-loop style core so every order executes deterministically without locks or context switches; sequencing is preserved by feeding work through in-order queues such that the leader’s log index is the single source of truth.
-
Co-located matching, OMS, and gateways inside an EC2 cluster placement group to shorten wire distance; pair this with dedicated tenancy, core pinning, and CPU C-state tuning so microbursts don’t suffer noisy-neighbor jitter.
-
Memory-map (mmap) the limit-order-book state, replay logs, and hot data blobs into userspace to bypass kernel copies; couple it with page pre-touching and huge pages so the matching thread always hits RAM and never stalls on page faults.
-
Replication pipeline uses Raft: leader appends each order to its WAL/log position, broadcasts append entries, waits for majority acks, then releases the decision to the matching loop; followers apply entries strictly in log order to maintain identical sequencing.
-
Leader election still follows Raft timing—followers monitor the leader heartbeat, start an election on timeout, gather a majority (using the highest replicated index as voting currency), and the new leader resumes sequencing from the last committed index so no order replays out of order.
So an Aeron[2] like system plays a crucial role, not only providing IPC event bus backed by memory for OMS and Matching engine, but also offering highly available leader election primitives when clustered over Raft.
- Aeron provides IPC via shared memory, event sequencing, and replication of messages across other hosts.
- Aeron also supplies leader election primitives to achieve failover within a few microseconds without data loss[7].
- In the AWS context, Aeron Premium can deliver kernel bypass capabilities to achieve ultra-low latency[6] using the EFA or even over the RDMA channel.
Coinbase International Exchange Architecture (Reference)
Coinbase’s architecture provides a blueprint for building cloud-native exchanges:
Core Components
Trading Systems
- Ultra-low latency, single-threaded, deterministic
- Clustered for resilience (Raft consensus)
- All nodes run the same code with the same input
Gateways
- Client connectivity via FIX, REST, and WebSockets
- Handle protocol translation and validation
- Can be scaled independently
Aeron Messaging / Simple Binary Encoding
- UDP-based messaging protocol
- Fast, reliable message delivery
- Built-in replication and archiving capabilities
Raft Cluster for Deterministic Consensus
The matching engine uses a Raft consensus algorithm to ensure all nodes process orders in the same order:
Key properties:
- One leader, multiple followers: Only the leader processes orders
- Majority consensus: Requires majority before processing
- Deterministic execution: All nodes run same code with same input
- Single-threaded: Avoids context switching overhead
- Built with Aeron: Open-source library for reliable messaging
Round-Trip Latency Breakdown
Coinbase’s latency performance demonstrates that cloud-based exchanges can achieve sub-millisecond latencies:
- Round trip time (networking + processing): Outliers < 1ms
- Networking time: ~80% of total (10 hops total)
- Processing time: ~20% of total (single-digit microseconds for OMS + Trading System)
The fact that networking dominates (80%) shows the importance of cluster placement groups and minimizing network hops. The processing time being in single-digit microseconds demonstrates the efficiency of single-threaded, deterministic execution.
Future Improvements
Coinbase identified several areas for future optimization:
Improving Client Connectivity Latency
Current State: Connectivity over Internet introduces variable latency
Future Options:
- AWS PrivateLink: Private connectivity for clients. Note: this option is available for derivative market exchange only.
- Shared cluster placement groups + VPC peering: Co-locate clients with exchange infrastructure
Networking and Latency Enhancements
- Kernel bypass: Reduce kernel overhead for network operations
- Elastic Network Adapter (ENA) Express: Enhanced networking features
- Elastic Fabric Adapter (EFA): For HPC-style workloads
Conclusion
Building a stock exchange in the cloud is not only possible but can provide own trade-off over traditional on-premises architectures:
- Lower operational overhead: Managed services for non-critical paths
- Better agility: Fast environment provisioning and safe deployment strategies
- Improved reliability: Cloud-native patterns for resilience and disaster recovery
- Cost efficiency: Pay only for what you use, scale on demand
- Go to the market and CapEx: Agility and self service provisioning at certain scale is the big win when its comes for goto the market. Business can avoid upfront spending when daily operational requiremetns and infrastructure footprintare still uncertain.
The key insight from Coinbase’s experience is that ultra-low latency and cloud-native design are not mutually exclusive. By carefully selecting instance types, using cluster placement groups, and optimizing network architecture, exchanges can achieve sub-millisecond latencies while maintaining the operational benefits of cloud infrastructure.
The next part of series would focus on Market data and reporting sections.
References
- [1]Coinbase: Building an ultra-low-latency crypto exchange on AWS - AWS re:Invent 2023 Session FSI309
- [2]Aeron Messaging - High-performance messaging library
- [3]AWS ENA with EC2
- [4]Raft Consensus Algorithm - Consensus algorithm for distributed systems
- [5]z1d Instances
- [6]Aeron performance enables capital markets to move to the cloud on AWS
- [7]Aeron Consensus Module
- [8]System deign interview - Alex Xu and Sahn Lam
- [9]ProofTrading - Prerak Sanghvi
- [10]Ciliums netkit